Síntese de proteínas – Entenda como as proteínas são fabricadas
A síntese de proteínas é a criação de proteínas pelas células utilizando DNA, RNA e várias enzimas.
A síntese de proteínas é o processo no qual as células produzem proteínas. Ocorre em duas etapas: transcrição e tradução. A transcrição é a transferência de instruções genéticas no DNA para o mRNA no núcleo. Inclui três etapas: iniciação, alongamento e terminação.
A atividade celular dos eucariotos varia entre dois estados típicos. Em um deles, a fabricação de proteínas é intensa, e o núcleo pode ser claramente observado.
Em seu interior podem ser vistas regiões que são coradas de maneira diferente, os nucléolos. Algumas células, dependendo de seu metabolismo, têm apenas um nucléolo evidente em seu núcleo, mas outras têm muitos deles.
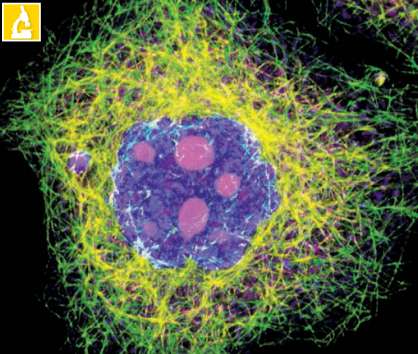
Em dado momento, a atividade no citoplasma diminui e são observadas mudanças no núcleo, e seus nucléolos desaparecem. Surgem estruturas em forma de bastão – os cromossomos condensados – e o envoltório nuclear desaparece. Este segundo estado corresponde ao período de divisão celular.
Vamos iniciar esta aula estudando a síntese de proteínas. Muitas dessas substâncias, como vimos, além de apresentarem função estrutural, têm também propriedades funcionais. As enzimas são proteínas específicas que controlam praticamente todas as reações metabólicas celulares. Participam da síntese de proteínas o DNA e três tipos de RNA, que serão apresentados a seguir: o RNA ribossômico, o RNA mensageiro e o RNA transportador.
No nucléolo é produzido um tipo de ácido nucleico chamado RNA ribossômico (RNAr). Ele é sintetizado a partir do DNA, composto por diferentes segmentos, que se entrelaçam assumindo uma conformação tridimensional muito específica. Se cada segmento tivesse uma cor diferente, o RNAr seria multicolorido.
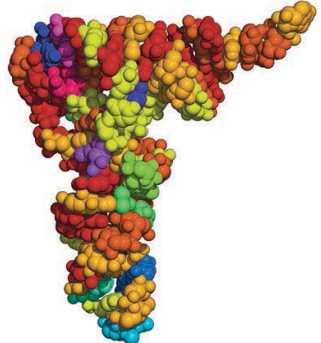
A geometria molecular do RNAr é muito importante e determina sua atuação na célula. O fato de o RNAr variar pouco entre diferentes seres vivos é interpretado como uma prova valiosa da relação de parentesco entre os diferentes organismos.
Os RNAr unem-se a proteínas e formam os ribossomos, estruturas que atuam na montagem de novas proteínas no citoplasma. Para tanto, eles precisam de uma “receita”, ou seja, de uma mensagem que contenha a identidade e a sequência de aminoácidos a serem ligados.
A mensagem para a produção de proteínas está contida no DNA. Nos eucariotos esse ácido nucleico está no interior do núcleo e a maquinaria de fabricação de proteínas está no citoplasma. Assim, é preciso que um mensageiro leve a informação do DNA até o ribossomo. Isso explica o nome do RNA mensageiro (RNAm), responsável por executar essa função. A transferência da informação genética do DNA para o RNAm é chamada transcrição e a leitura da mensagem presente no RNAm recebe o nome de tradução.
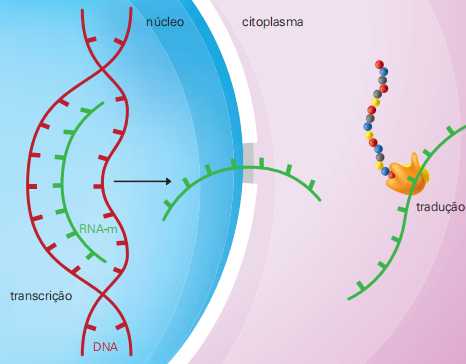
O esquema acima mostra as etapas de transcrição e tradução em eucariotos: no núcleo, a informação para a confecção de uma proteína passa da fita-molde do DNA para o RNA mensageiro (RNAm), caracterizando a transcrição; no citoplasma é feita a tradução, isto é, a leitura da mensagem do RNAm, em interação com os ribossomos, onde ocorre a fabricação das proteínas.
Transcrição
Transcrição é o processo pelo qual o DNA é copiado para o RNA. Esse processo, que ocorre no núcleo, o pareamento das bases nitrogenadas é desfeito em um pequeno trecho do DNA e uma das fitas, a chamada fita-molde, é utilizada para confeccionar uma fita simples de RNA.
Conforme ocorre a separação das cadeias de DNA, ribonucleotídeos livres ligam-se às bases nitrogenadas da fita-molde, formando a molécula de RNA. Isso é feito com as bases nitrogenadas complementares, que não são idênticas nos dois ácidos nucleicos.
Os ribossomos dos eucariotos são muito maiores do que os ribossomos dos procariotos. Os ribossomos das células com núcleo organizado em massa molecular de 4 200 kDa (a unidade dalton se refere à massa atômica e corresponde a 1/12 da massa do carbono 12), isto é, aproximadamente a massa de 4,5 milhões de átomos de hidrogênio. Já a massa molecular dos ribossomos de procariotos é quase a metade disso, sendo de 2 500 kDa. Isso é considerado um dado fundamental para entender as relações de parentesco entre os grandes grupos de seres vivos.
Veja o quadro abaixo com as bases nitrogenadas dos dois ácidos nucleicos que se complementam na transcrição.
| DNA | RNA |
| Adenina (A) | Uracila (U) |
| Timina (T) | Adenina (A) |
| Guanina (G) | Citosina (C) |
| Citosina (C) | Guanina (G) |
Quando uma proteína vai ser fabricada, uma região do DNA do núcleo da célula (DNA genômico) é copiada por uma en- zima chamada RNA polimerase.
A RNA polimerase se desloca pela hé- lice do DNA e promove o desenrolamento da forma helicoidal de pequena região da molécula de ácido desoxirribonucleico.
Na região em que a dupla hélice se separa, inicia-se a formação da fita de RNAm: os nucleotídeos com ribose (ribonucleotídeos) ligam-se às bases nitrogenadas da fita-molde de DNA, formando uma curta fita dupla híbrida.
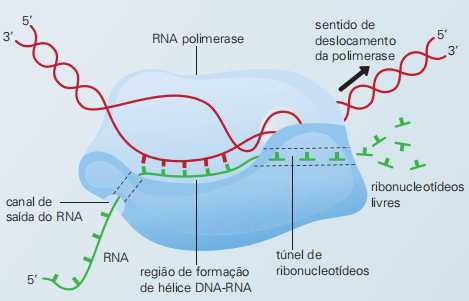
Apenas um dos lados da molécula de DNA é reconhecido pela RNA polimerase, que transcreve a informação da fita-molde formando uma molécula de RNAm. Chamamos de gene esse segmento de DNA codificador. O gene contém informação e pode ser transcrito em RNAs de diversos tipos e traduzido em proteínas.
O conjunto de informações genéticas forma o genoma da espécie. Essa informação pode ser a receita para a construção de uma proteína, e, nesse caso, o RNA produzido será uma molécula de fita simples em toda sua extensão.
Vários tipos de RNA são produzidos no núcleo celular. Como vimos, alguns deles formam os ribossomos (RNAr) e se deslocam para o citoplasma; outros levam informação para a fabricação de proteínas no citoplasma (RNAm). Uma vez pronto, o RNA originado de uma região genômica que codifica proteínas forma o RNA mensageiro “maduro”, ou simplesmente RNAm. Veremos adiante como o RNAm traduz a mensagem que carrega.
Tradução
Tradução proteica é o processo em que ocorre a decodificação de instruções para a produção de proteínas, envolvendo tanto o mRNA na transcrição quanto o tRNA.
O RNA contendo a mensagem com a sequência de aminoácidos a serem unidos se desloca até o citoplasma, onde irá interagir com os ribossomos. Como você já viu, as proteínas são formadas a partir de cadeias lineares de aminoácidos.
Sintetizar uma proteína, portanto, significa, pelo menos como tarefa inicial, ligar certos aminoácidos em uma sequência específica: a insulina, por exemplo, é constituída de aminoácidos ligados em uma determinada ordem (reveja, no capítulo 3, os itens “Ligando aminoácidos: ligação peptídica” e “A estrutura das proteínas”).
Quando o RNAm tem uma sequência de bases nitrogenadas citosina (C-C-C), essa trinca determina que seja acrescentado o aminoácido prolina (PRO) à proteína em formação.
Caso ela seja sucedida por outra trinca, com três moléculas de uracila (U-U-U), será acrescentado na sequência o aminoácido fenilalanina (PHE). Uma terceira trinca apenas com moléculas de adenina (A-A-A) determinará a colocação, em terceiro lugar, do aminoácido lisina (LIS). Assim funciona o código das bases nitrogenadas, o chamado código genético.
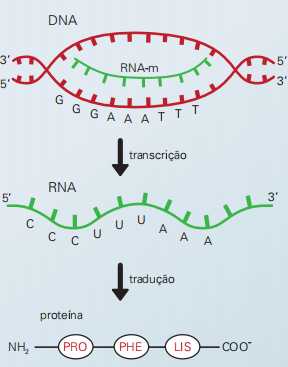
Acima está uma representação esquemática das etapas envolvidas na passagem da informação genética de um segmento de DNA até a formação de uma proteína. Note a correspondência entre as bases nitrogenadas do DNA e do RNA e entre a trinca de bases nitrogenadas do RNAm e os aminoácidos por elas determinados
Chamamos de códon a trinca de bases nitrogenadas do RNAm com algum significado na tradução. Nem todos os códons têm aminoácidos correspondentes.
Alguns deles podem significar o encerramento da tradução, por exemplo, as trincas U-A-A e U-A-G, os chamados códons de terminação. Por outro lado, o códon A-U-G tanto pode significar o início da tradução como, se estiver no meio da mensagem, representar o acréscimo do aminoácido metionina. A cada trinca de bases do RNAm, portanto, corresponde um aminoácido específico ou, então, uma sinalização de início ou final da informação genética na molécula de RNAm.
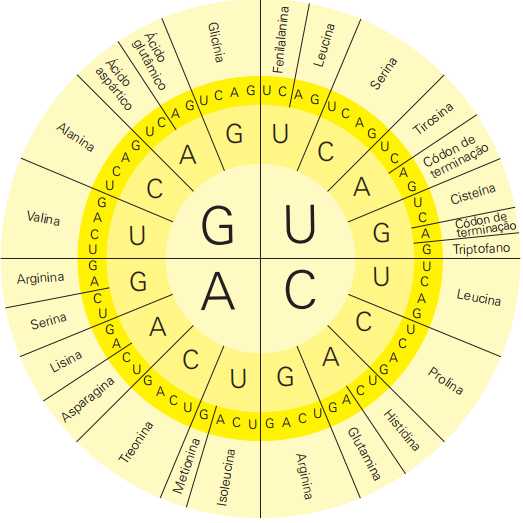
O código genético é a correspondência entre as trincas de bases nitrogenadas do RNA e os aminoácidos. Esse código é altamente conservado, ou seja, quase todos os organismos sintetizam proteínas a partir dele. Veja como a citosina na primeira, na segunda e na terceira posições (CCC) significa o aminoácido prolina. Da mesma forma, UUU significa fenilalanina e AAA significa lisina.
Não existe uma explicação consensual para o fato de diversas trincas codificarem o mesmo aminoácido, ou seja, a razão de o código ser degenerado. No entanto, descobertas recentes de pesquisadores brasileiros, apontam para regularidades matemáticas na sequência de bases do DNA capazes de corrigir erros de replicação; isso nos permitiria entender que sem a degeneração do código genético a regularidade matemática das sequências nucleotídicas não seria possível.
Observe que um mesmo aminoácido é codificado por mais de uma trinca. Por exemplo, localize o aminoácido fenilalanina, na parte superior da tabela circular e veja que há duas letras (U, C) a designar a terceira base da trinca. Isso quer dizer que tanto a trinca UUU quanto a trinca UUC designam esse aminoácido.
Outros aminoácidos, como a serina, são codificados por até seis diferentes trincas de bases nitrogenadas. Por essa razão, dizemos que o código genético é degenerado. No entanto, ele não possui ambiguidades, ou seja, uma trinca específica codifica apenas um aminoácido. Além disso, esse mesmo código tem sido encontrado em praticamente todos os organismos estudados, o que indica que ele é universal.
Os ribossomos fabricados no nucléolo atuam na síntese de proteínas, interpretando a mensagem do RNAm. Observe na figura abaixo um desenho artístico de um ribossomo em ação.
A atuação do ribossomo na síntese de proteínas pode ser entendida de maneira simplificada a partir do fato de que ele não reconhece diretamente os aminoácidos. Uma parte do RNA produzido no núcleo é composta de segmentos relativamente curtos, com 80 nucleotídeos.
As moléculas desse RNA ligam-se especificamente a determinados aminoácidos, em um dos lados, e do outro lado mantêm exposta uma trinca de bases nitrogenadas, denominada anticódon. São os RNA transportadores (RNAt).
Eles são especiais porque possuem, entre outras características distintivas, algumas bases nitrogenadas modificadas e pareamentos em certas regiões de sua fita simples.
Embora seja correto afirmar que o código genético é universal, existem pequenas diferenças no código genético padrão. O fungo patogênico Candida albicans traduz o código CUG como serina, enquanto quase todos os outros organismos conhecidos o traduzem como leucina.
A mitocôndria, que tem DNA próprio, tem algumas diferenças. Por exemplo, em mamíferos, AUA é traduzido pela mitocôndria como metionina, mas no citoplasma a trinca é traduzida como isoleucina.
Veja na figura abaixo um RNAt carregando o aminoácido fenilalanina e uma representação mais detalhada do mesmo RNAt.
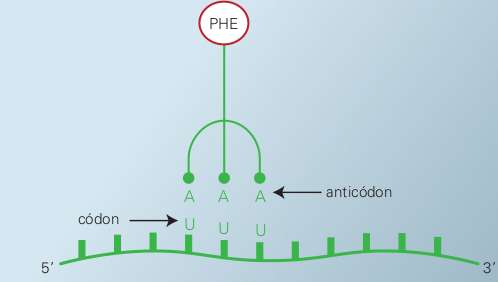
Abaixo, representação do RNA transportador, que possui um anticódon em uma das alças, em azul, e está ligado a um aminoácido (neste caso, a fenilalanina), mostrado em verde.
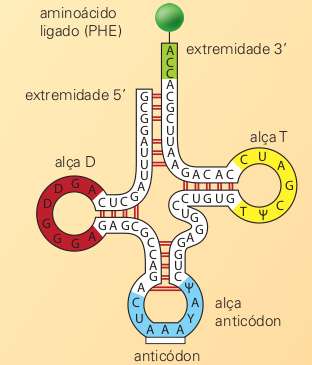
À medida que o ribossomo se desloca pelo RNAm, os RNAt ligados a aminoácidos são recrutados e ocorre o reconhecimento entre códon e anticódon.
A síntese de uma proteína ocorre pela sequência de acoplamento do RNAt no ribossomo e pela ligação dos aminoácidos incorporados à proteína, promovida pelo ribossomo. Veja na figura abaixo, um esquema da sequência em cinco etapas (A, B, C, D, E) para a formação de uma proteína.
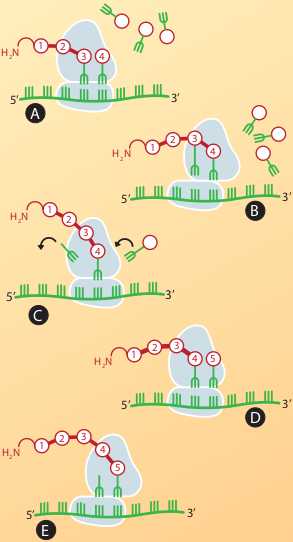
Observe, na etapa A, como três aminoácidos unem-se, formando o começo da cadeia polipeptídica, e um RNAt se acopla ao códon do RNAm. Na etapa B, observe como, com o deslizamento da subunidade maior do ribossomo, é promovida a ligação peptídica entre o aminoácido 4 e o 3. Em C, com o deslizamento da subunidade menor, o RNAt, ligado ao aminoácido 3, desprende-se do RNAm e do ribossomo. A saída do RNAt libera uma posição no ribossomo para acoplamento do próximo RNAt, que traz o aminoácido 5 (etapa D), e assim recomeça o ciclo. Em E repete-se a etapa B, ou seja, é promovida a ligação peptídica entre o aminoácido adicionado e a cadeia polipeptídica em construção.
O anticódon do RNAt que carrega o aminoácido emparelha com o códon da extremidade da molécula do RNAm, dando início à tradução da proteína.
A molécula de RNAm é lida até o aparecimento de um códon de terminação. A proteína é então finalizada deixando o ribossomo disponível para o acoplamento de outro RNAt. Vários ribossomos podem percorrer a mesma molécula de RNAm, formando um polissomo.
Uma bactéria pode ter cerca de 20 mil ribossomos, ao passo que uma célula muito ativa de mamífero chega a conter 10 milhões de ribossomos.